Bayesian inference
In statistics, Bayesian inference is a powerful method for updating a probability estimate when new data becomes available. This process can be seen as an elegant extension of traditional maximum likelihood estimation (MLE) that incorporates prior beliefs or knowledge into the analysis.
The Bayes’ Theorem
The foundation of this method is the Bayes’ theorem, which provides the formula for calculating the posterior probability.
\[P(\theta \mid X) = \frac{P(X \mid \theta) P(\theta)}{P(X)}\]Here
- $\theta$ stands for a hypothesis or a set of parameters according to a particular hypothesis.
- $P(\theta)$ is the prior probability. This is our initial belief or knowledge about the hypothesis before we observe any data. It reflects what we know (or assume) from past experience or domain expertise.
- $P(X \mid \theta)$ is the probability of observing the new data ($X$) given our hypothesis ($\theta$) is true. In Bayesian inference, this term is calculated using a likelihood function, similar to how it’s used in MLE.
- $P(\theta \mid X)$ is the posterior probability of the hypothesis after observing the data $X$.
- $P(X)$ is the Evidence or Marginal Likelihood. This is the total probability of observing the data, averaged over all possible hypotheses. It acts as a normalization constant, ensuring the posterior probability sums to 1.
The evidence term $P(X)$ is the sum of the joint probabilities of the data and all possible hypotheses. For a continuous parameter space, this is an integration over all possible values of $\theta$:
\[P(X) = \int_{\theta} P(X \mid \theta) P(\theta) d\theta\]This allows us to rewrite the Bayes’ theorem in a more complete form:
\[P(\theta \mid X) = \frac{P(X \mid \theta) P(\theta)}{\int_{\theta} P(X \mid \theta) P(\theta) d\theta}\]Derivation of the The Bayes’ Theorem
The Bayes’ theorem is derived from the notion of conditional probability. Let’s say we have two events: $A$ and $B$. The conditional probability $P(A\mid B)$ can be intuitively understood as the fraction of probability of event $B$ which intersects with the probability of event $A$: $\frac{P(A\cap B)}{P(B)}$.
Returning to the Bayes’ theorem, both $P(\theta \mid X)$ and $P(X \mid \theta)$ can be expressed in a similar manner using the intersection of probabilities. Then
\[P(\theta \mid X) \cdot P(X) = P(X \mid \theta) \cdot P(\theta)\] \[\frac{P(\theta \cap X)}{P(X)} \cdot P(X) = \frac{P(\theta \cap X)}{P(\theta)} \cdot P(\theta)\]which proves the original formula.
A Simple Example: The Cafe Tipping Problem
Let’s illustrate the process with a simple example. Suppose a cafe owner knows that, historically, about 60% of all customers leave a tip. This is their prior belief.
In a recent week, the cafe served 287 customers, and 123 of them left a tip. The owner wants to update their belief about the true tipping probability based on this new data.
-
Prior: The owner’s initial belief that the true tipping probability is 60%.
-
Likelihood: The probability of observing exactly 123 tips out of 287 customers, given some hypothetical tipping probability.
-
Posterior: The updated belief about the tipping probability after seeing the 123 tips.
The core of Bayesian inference is this iterative loop: Posterior becomes the new Prior as new data arrives.
Methods of Bayesian Inference
Maximum a Posteriori (MAP) Estimation
The Maximum a Posteriori (MAP) estimation method finds the value of θ that maximizes the posterior probability.
This is very similar to [MLE] (/optimization/maximum-likelihood/), but it includes the prior probability. Since the denominator in Bayes’ rule, $P(X)$, is a constant with respect to $\theta$, we can simply maximize the numerator to find the mode of the posterior distribution:
\[\theta_{MAP} = \arg \max_{\theta}[P(X \mid \theta) P(\theta)]\]In our cafe example, the likelihood $P(X \mid \theta)$, can be modeled by a binomial distribution, and the prior $P(\theta)$,can be modeled by a beta distribution. The beta distribution is an excellent choice because it is the conjugate prior of the binomial distribution, meaning the resulting posterior will also be a beta distribution.
The owner’s historical knowledge of a 60% tip rate can be represented by a beta distribution with parameters $\alpha=60$ and $\beta=40$. The new data is 123 successes out of 287 trials.
The expression $P(X \mid \theta) P(\theta)$ can be rewritten as product of densities of the two distributions:
\[\begin{align*} P(X \mid \theta) P(\theta) &= \binom{n}{k} \theta^{k}(1-\theta)^{n-k} \frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)} \theta^{\alpha -1}(1-\theta)^{\beta -1} \\ &= \binom{n}{k} \frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)} \theta^{k+\alpha-1}(1-\theta)^{n-k+\beta-1} \end{align*}\]The point of maximum is obtained by taking the derivative of this expression with respect to $\theta$ and setting it to zero, which further boils down to this:
\[\theta = \frac{k+\alpha-1}{n+\alpha+\beta-2}\]In our example the updated value of the probability of tipping becomes (123+60-1)/(287+60+40-2) which is approximately 47%. Let’s also see how all three probabilities are distributed on the scale from 0 to 1.
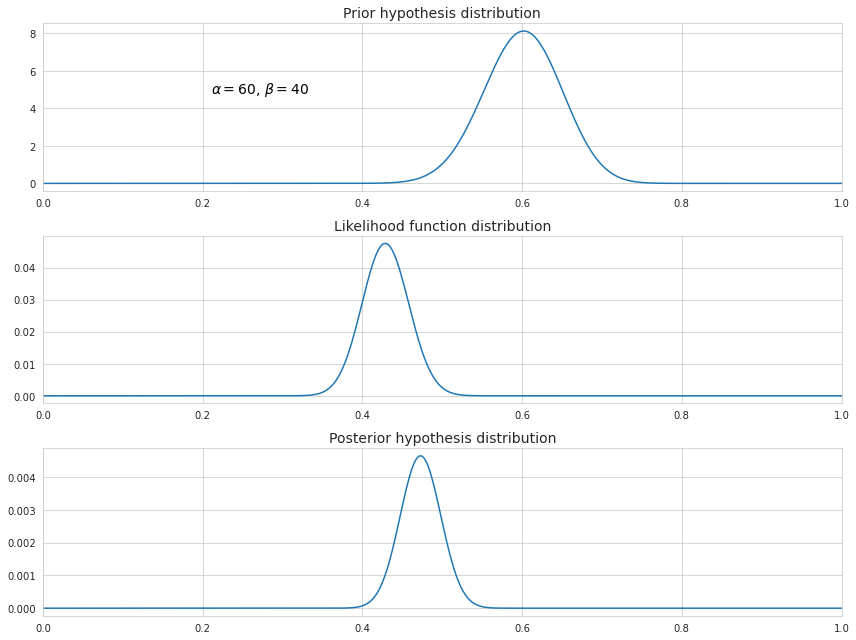
As we can see, the existence of the prior hypothesis slightly shifted the distribution resulting from the MLE towards bigger values. In addition, its values are less spread around its mean because now the distribution incorporates more data.
Note that the choice of $\alpha$ and $\beta$ may significantly impact the posterior distribution. Greater values means higher confidence in the prior hypothesis, so that it has more weight in determining the posterior.
Also note that since we have omitted dividing by $P(X)$ in the calculation of the posterior distribution the function above is not scaled, so it’s not quite the same as the probability density function.
Expected a posteriori estimation (EAP)
This is yet another method of Bayesian inference which is based on the mean of the posterior distribution instead of its mode as is the case with the MAP. Since the posterior is beta-distributed, it is not symmetric, and the mean is usually not equal to the mode.
The mean is calculated through integration over $\theta$ for each possible value of $\theta$ multiplied by its probability density function.
\[E[P(\theta \mid X)] = \int_{\theta} \theta P(\theta \mid X) d\theta = \frac{k+\alpha}{n+\alpha+\beta}\]Markov Chain Monte Carlo (MCMC)
For complex, real-world problems where the posterior distribution does not have a simple form (and therefore MAP/EAP are not easily calculated), Markov Chain Monte Carlo (MCMC) methods are used. MCMC algorithms like the Metropolis-Hastings or Gibbs sampler do not solve the full Bayes’ rule equation directly. Instead, they cleverly draw thousands of samples from the posterior distribution. These samples can then be used to approximate the posterior’s shape, mean, and credible intervals, making Bayesian inference possible for a huge range of problems.